Overview
kapa is a retrieval augmented generation system (RAG). To set up an instance of kapa you have to ingest all relevant technical knowledge which is required to answer the questions of the intended audience. To answer questions, kapa first performs a search over an index created from the ingested knowledge sources and then uses LLMs to generate the final output. Users can manage their data sources in the kapa platform.
The kapa platform makes handling data sources easy with:
- Automated Refreshing: sources are automatically refreshed on a custom schedule (e.g., daily, weekly, monthly).
- One-Click Source Connectors: out-of-the-box integrations with popular knowledge sources (e.g., Web Crawling, GitHub, Slack).
- Optimal Formatting for LLMs: we abstract away the complexity of formatting data sources for LLMs behind the scenes.
The sections below outline how to effectively set up and manage data sources on the kapa platform.
Our kapa team is ready to support you in setting up your data sources. Don't hesitate to contact us for any assistance required.
Step 1: Add New Data Source 📥
On the source page click on the Add new source button in the top right corner and choose one of the available integrations. After making a selection a corresponding configuration screen will open.
|
Head over to the Supported Data Sources page to see the full list of supported data sources. More sources are being added every week.
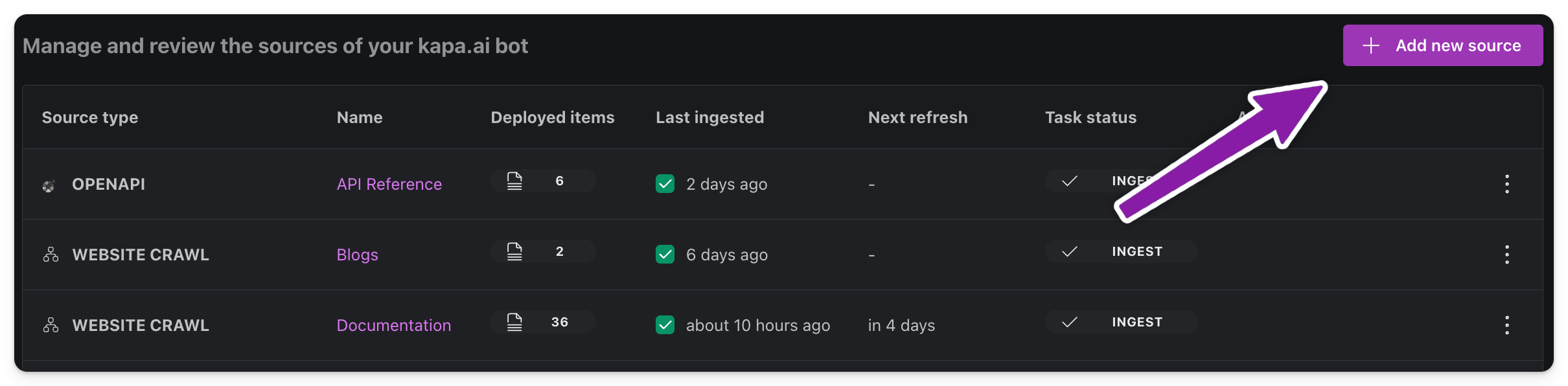
Step 2: Check Source Status 📊
After completing the configuration for a source kapa retrieves the source's full data. Depending on data size this can take a few minutes. The status of the source will tell you when it is done. In the example below you can see that the convert step for a Website Crawl source has completed. Now the source is ready for review.

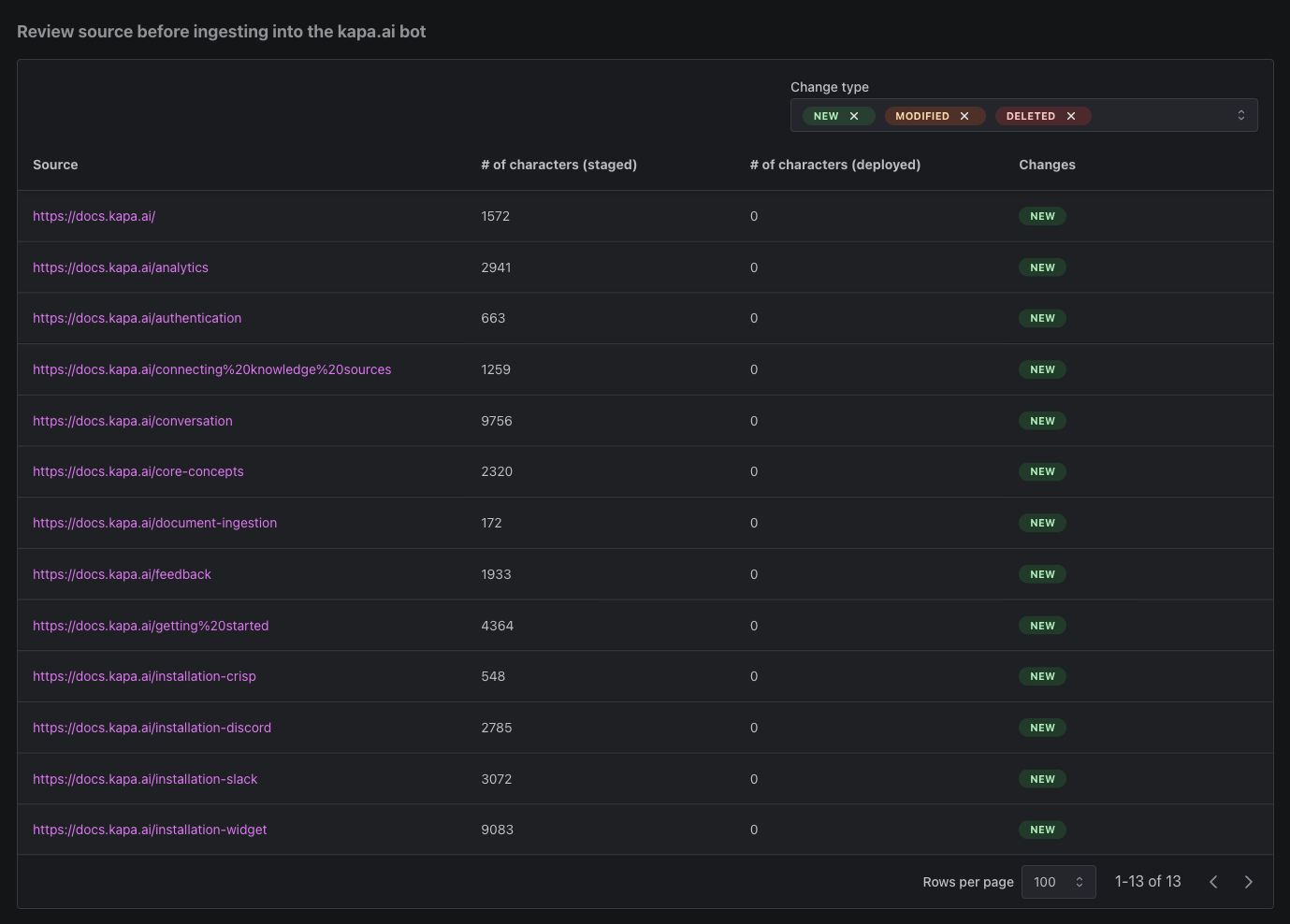
Step 3: Review the Source ✅
Before ingesting a new source kapa forces the user to review the full content that will be added to the kapa instance. This is equivalent to a PR review before merging to main. Once all configuration steps for a source are completed the user is prompted to review. The below example screen shows the git diff style review screen. Similiarilly users are prompted to review after one of their sources has refreshed automatically. After reviewing users can trigger the ingestion of their source from the review screen.
Step 4: Ingesting the Source 🚀
Ingestion is the process of inserting or replacing a data source into the search index of a kapa instance. After a source has been successfully ingested the kapa instance is aware of the contents of the source. As shown in the example below ingested sources have a Last ingested attribute. The ingestion of a source is triggered from the review screen.

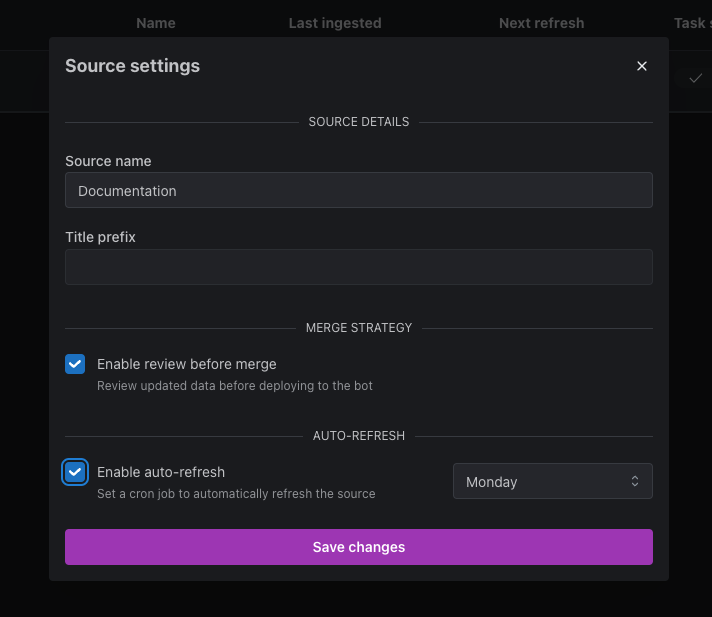
Step 5 (Optional): Configure Sources to Auto-Refresh 🔄
kapa lets users automatically refresh their sources on a schedule once they have been set up for the first time. This can be configured from the settings of the source as shown in the example bewlow. During a refresh all tasks for pulling and converting the content of a source are run automatically. By default the refresh ends in a review but this can be disabled to ingest the refreshed content immediately.